Exam text content
SGN-24007 Advanced Audio Processing - 28.02.2020
Exam text content
The text is generated with Optical Image Recognition from the original exam file and it can therefore contain erroneus or incomplete information. For example, mathematical symbols cannot be rendered correctly. The text is mainly used for generating search results.
Original exam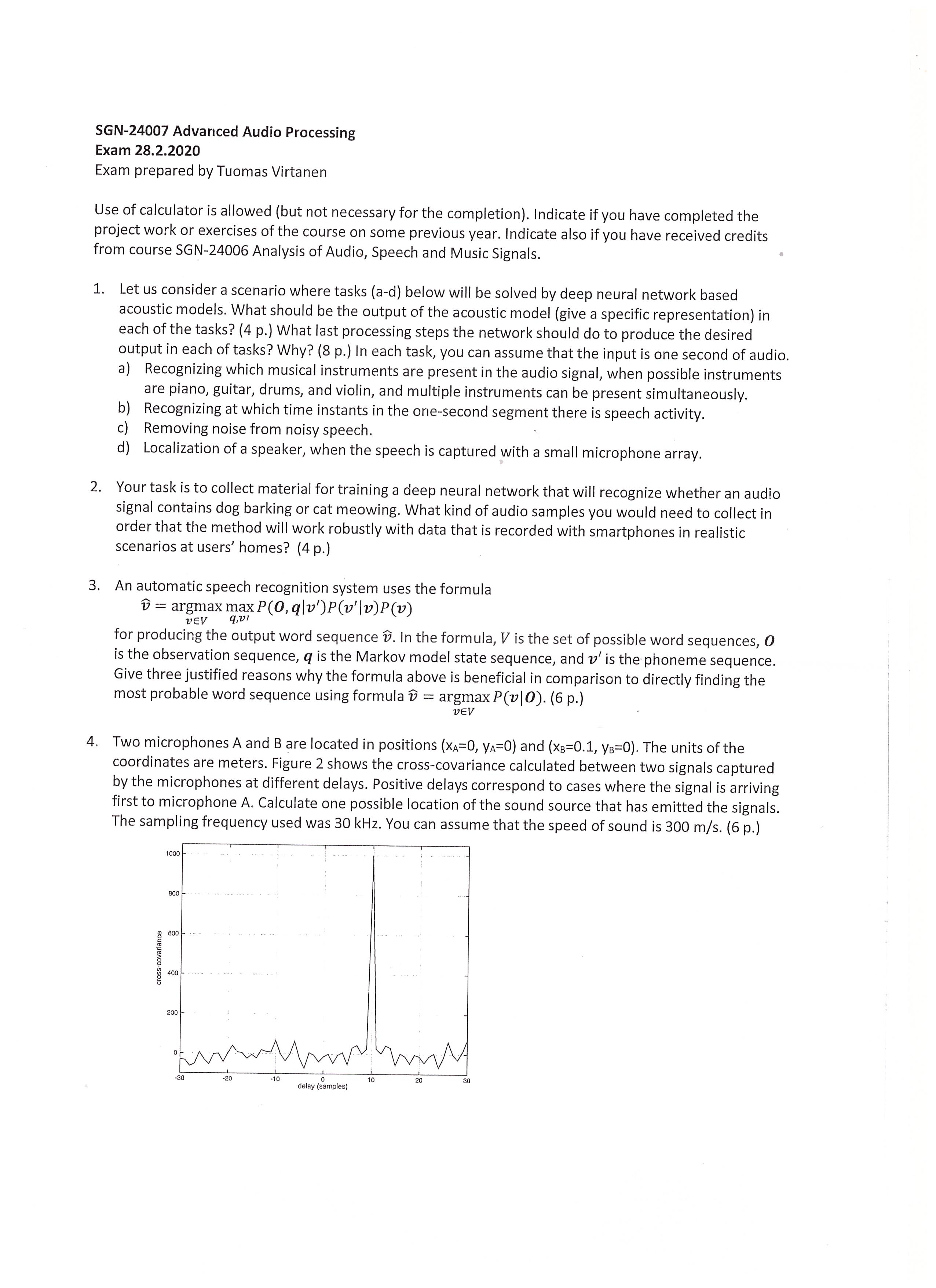{kind=link}
SGN-24007 Advanced Audio Processing Exam 28.2.2020 Exam prepared by Tuomas Virtanen Use of calculator is allowed (but not necessary for the completion). Indicate if you have completed the project work or exercises of the course on some previous year. Indicate also if you have received credits from course SGN-24006 Analysis of Audio, Speech and Music Signals. 1. Letusconsidera scenario where tasks (a-d) below will be solved by deep neural network based acoustic models. What should be the output of the acoustic model (give a specific representation) in each of the tasks? (4 p.) What last processing steps the network should do to produce the desired output in each of tasks? Why? (8 p.) In each task, you can assume that the input is one second of audio. a) Recognizing which musical instruments are present in the audio signal, when possihle instruments are piano, guitar, drums, and violin, and multiple instruments can be present simultaneously. b) Recognizing at which time instants in the one-second segment there is speech activity. c) Removing noise from noisy speech. ä d) Localization of a speaker, when the speech is captured with a small microphone array. 2. Yourtaskisto collect material for training a deep neural network that will recognize whether an audio signal contains dog barking or cat meowing. What kind of audio samples you would need to collect in order that the method will work robustly with data that is recorded with smartphones in realistic scenarios at users' homes? (4p.) 3. An automatic speech recognition system uses the formula D = argmax max P(0,gl|v')P(v'|v)P (v) veEv av! for producing the output word seguence %. In the form ula, V is the set of possible word seguences, 0 is the observation seguence, g is the Markov model state seguence, and v' is the phoneme seguence. Give three justified reasons why the formula above is beneficial in comparison to directly finding the most probable word seguence using formula D = argmax P(v|O). (6 p.) VEV 4. Two microphones A and B are located in positions (xa=0, Ya=0) and (xs=0.1, ys=0). The units of the coordinates are meters. Figure 2 shows the cross-covariance calculated between two signals captured by the microphones at different delays. Positive delays correspond to cases where the signal is arriving first to microphone A. Calculate one possible location of the sound source that has emitted the signals. The sampling freguency used was 30 kHz. You can assume that the speed of sound is 300 m/s. (6 p.) T T T T 1000 + i i 4 800 — 600 +. 4 4 400 cross-covariance 200 1 i 1 i o 20 30 delay (samples)
{kind=link}
{kind=link}